
Wofür steht das?
EDIFACT steht für Electronic Data Interchange for administration, commerce and transport. Da dieser Nachrichtenstandard von einer Abteilung der vereinten Nationen, der UNECE (United Nations Economic Commission for Europe) bzw. deren Unterabteilung CEFACT gepflegt wird, nennt man diesen Standard auch oft UN/EDIFACT. Und da das letzte E in UNECE für Europe steht, wird in Übersee (USA, Australien, …) lieber das prinzipiell ähnliche, aber eben doch wieder andere X12 verwendet. Dazu gibt’s einen eigenen Artikel.
EDIFACT beschreibt ein Datenformat, das heißt den Aufbau von Nachrichten. Und das sind verdammt viele: In der Version D12B werden fast 200 Nachrichtentypen definiert. Version D12B? Das bedeutet: Verzeichnis der Nachrichtentypen (D für directory), Stand des Jahres 2012, zweite Ausgabe. Üblicherweise gibt es zwei Ausgaben jedes Jahr, in denen neue Nachrichten aufgenommen und bestehende verändert (meist erweitert) werden, und diese beiden Ausgaben heißen A und B. Im Jahre 2001 gab es aber auch noch eine dritte Ausgabe, C.
Netterweise werden die Nachrichtenbeschreibungen jeder Version allgemein zugänglich gemacht, man kann sie bei der UNECE einfach herunterladen. Gut, in einem scheußlichen Textformat, aber immerhin, sie sind kostenlos zu haben.
Varianten alias Subsets
Die UNECE gibt sozusagen den Standard für EDIFACT heraus, wobei sie für alle möglichen Branchen und Einsatzgebiete Nachrichten definiert. Das ist toll, aber wie es so ist, es möchte halt doch jeder sein eigenes Süppchen kochen. In diesem Fall nennen sich diese Süppchen Subsets und bestehen zwar prinzipiell aus denselben Zutaten, aber nur denen, die in einer bestimmten Branche bzw. Anwendergruppe interessant sind. Die Auswahl der genutzten Nachrichtentypen und auch deren Aufbau sind zusammengestutzt auf das, was man jeweils für ausreichend hält. Beispiele für diese Subsets sind EANCOM (Konsumgüterindustrie), EDIFOR (Speditionen), EDIWHEEL (Reifenhandel) und ODETTE (von der gleichnamigen Organisation, für die Automobil-Industrie). Zumindest theoretisch sollten die Nachrichten dieser Subsets so aufgebaut sein, dass sie ebenso gut in den Strukturen des UN-Standards Platz haben. Das heißt, es können Segmente, Segmentgruppen und auch Felder weggelassen werden, aber nur, wenn sie im Standard keine Pflicht sind. Allerdings dürfen eigene Qualifier definiert werden. Was das alles ist, erfahren Sie im Folgenden.
Genereller Aufbau
Wie ist nun so eine EDIfact-Nachricht aufgebaut? Zum Beispiel so:
UNA:+.?'
UNB+UNOC:3+ILNAbsender+ILNEmpfänger+130230:1025+98765'
UNH+1+ORDERS:D:96A:UN'
BGM+220+9'
DTM+4:20130230:102'
NAD+SU+++Hardwarequelle+Ladenstraße 1+Nirgendwo+NRW+54321+DE'
NAD+BY+++Lobster:GmbH+Münchnerstr.15a+Starnberg+BAY+82319+DE'
LIN+1++4711:SA'
IMD+++::USB-Stick'
QTY+1:100'
UNS+S'
CNT+2:1'
UNT+11+1'
UNZ+1+98765'
Auf unterster Ebene
Dröseln wir das Ganze mal von unten auf. Sie sehen hier einzelne Zeilen, die jeweils ein sogenanntes Segment enthalten. Wobei die Zeilen aber letztlich nur der Lesbarkeit dienen und keine Pflicht sind. Ebensogut könnte die ganze Nachricht in einer einzelnen Zeile stehen oder (sehr beliebt bei Nutzern einer AS400 alias IBM iSeries) im 80-Zeichen-Blocksatz. Das sähe dann so aus:
UNA:+.?'UNB+UNOC:3+ILNAbsender+ILNEmpfaenger+130230:1025+98765'UNH+1+ORDERS:D
:96A:UN'BGM+220+9'DTM+4:20130230:102'NAD+SU+++Hardwarequelle+LadenstraSSe1+Nirgen
dwo+NRW+54321+DE'NAD+BY+++Lobster:GmbH+Hindenburgstr15+Poecking+BAY+82343+D
E'LIN+1++4711:SA'IMD+++::USB'QTY+1:100'UNS+S'CNT+2:1'UNT+11+1'UNZ+1+98765'
Nicht schön? Aber ebenso gültig. Denn am Ende jedes Segments steht ein einfaches Hochkomma (‚), das als Ende-Markierung vereinbart ist (und außerdem Standard). Daher sind Zeilenumbrüche völlig unnötig. Wie Sie im Blocksatz sehen, werden sogar Werte mittendrin geteilt. Das stört nicht. Jede Software, die EDIFACT einlesen kann, fügt die Werte wieder ordentlich zusammen (zumindest sollte sie das …).
Was ist nun so ein Segment? Jedes Segment besteht aus einer Segmentkennung (UNA, UNB, UNH, …) und Werten. Die Kennung besteht immer aus drei Buchstaben und sagt aus, worum es geht. QTY beispielsweise steht für QUANTITY, also eine Mengenangabe, während NAD für NAME AND ADDRESS steht. Segmentkennungen mit UN am Anfang haben spezielle Bedeutung und sind nicht vom Nachrichtentyp abhängig. Die wichtigsten dieser allgemeinen Segmente sind: UNA, UNB, UNH, UNT und UNZ. Sie werden später im Einzelnen erläutert.
Die Werte innerhalb eines Segments werden durch zwei verschiedene Zeichen getrennt, im Beispiel das Plus und der Doppelpunkt. Warum zwei verschiedene? Weil es nicht einfach nur Felder innerhalb eines Segments gibt, sondern auch sogenannte Composite elements, kurz Composites. Das sind mehrere Felder, die sinngemäß zusammen gehören. Im UNB-Segment sind beispielsweise das Datum und der Zeitpunkt der Nachricht in einer Composite zusammengefasst: 130230:1025, also 30. Februar 2013 (ja, das ist Absicht) um
10 Uhr 25. Eigenständige Felder werden voneinander und von den Composites durch das Plus getrennt, Felder innerhalb von Composites durch den Doppelpunkt. Hat ein Feld keinen Wert, aber danach kommt noch was, werden die nötigen Trennzeichen angegeben, damit die Reihenfolge gewahrt bleibt. Ein schönes Beispiel sehen wir oben beim IMD-
Segment: IMD+++::USB-Stick. Hier ist erst das dritte Feld einer Composite mit einem Wert belegt, und auch die beiden Felder vor der Composite sind leer. Kommt nach einem Wert gar nichts mehr im Segment oder dieser Composite, können die Trennzeichen auch wegfallen.
Ein Beispiel wäre: NAD+SU+12345‘
Sollte eines der Trennzeichen zufällig auch in einem Wert vorkommen, muss es maskiert werden, damit es als normales Zeichen durchgeht. Im Standard geschieht das durch ein Fragezeichen:
Aus „Firma Reibach + Söhne“ wird also Firma Reibach ?+ Söhne. Und sollte das ? selbst im Wert stehen, wird es ebenfalls – mit sich selbst – maskiert: „Alles klar??“
Soweit zur untersten Ebene des Datenformates.
Grober Aufbau einer EDIFACT-Datei
Gehen wir nun ganz „nach oben“, zum Aufbau jeder EDIFACT-Datei. Bestimmte Segmente kommen in jeder Datei vor, ganz egal, worum es darin geht. Diese allgemeinen Segmente nennt man auch Steuersegmente, und sie klammern jede EDIFACT-Datei bzw. -Nachricht:
UNA (optional, falls andere Sonderzeichen als im Standard verwendet werden, s.u.)
UNB (verpflichtend, genau 1 Mal am Anfang der Datei)
UNG (optional, klammert Gruppe mehrerer Nachrichten des selben Typs)
UNH (verpflichtend, 1 Mal pro Nachricht, n mal innerhalb einer Gruppe oder Datei, Header-Informationen)
Eine einzelne Nachricht
UNT (verpflichtend, Ende-Segment zu UNH, also 1 Mal pro UNH)
UNE (optional, Ende-Segment zu UNG, also 1 Mal pro UNG und bei dessen Verwendung auch Pflicht)
UNZ (verpflichtend, Ende-Segment zu UNB, genau 1 Mal am Ende der Datei)
Strukturierung einzelner Nachrichten
So, und nun bleibt noch der Aufbau einer einzelnen Nachricht. Der ist leider nicht ganz einfach. Welche Segmente in welcher Reihenfolge kommen, wird durch den Typ der Nachricht bestimmt. Allerdings kann dieselbe Art Segment innerhalb einer Nachricht an unterschiedlichen Stellen stehen und dann auch, je nach Kontext, unterschiedliche Bedeutung haben. Als Beispiel wählen wir hier die Nachricht APERAK in der Version D96A. APERAK steht
für „Application error and acknowlegement“. Schon doof, wenn man sich immer auf exakt sechs Zeichen als Nachrichtenname festlegen muss …

Diese Nachricht wurde schlicht deshalb ausgewählt, weil sie recht einfach aufgebaut ist und alles in einem kleinen Bildchen Platz hat. Sie wird genutzt, um dem Absender von Daten anzuzeigen, ob es mit seiner Datei inhaltliche bzw. fachliche Probleme gab oder alles in Ordnung ist.
Sie sehen die Steuersegmente UNB, UNH, UNT und UNZ (UNG/UNE sind für den Inhalt nicht wirklich von Bedeutung und fehlen daher) und dazwischen, ab BGM, die eigentliche Nachricht. BGM steht für „Beginning of message“ und kommt in jeder Nachricht verpflichtend vor.
Dass es ein Pflichtsegment ist, erkennt man an dem roten Stern im Kästchen. Optionale
Segmente bzw. Segmentgruppen (kommt gleich) haben einen blauen Stern.
Gerade fiel das Wort „Segmentgruppe“. Im Bild sind das SG1, SG2, SG3 und darin noch SG4
(SG für Segmentgruppe). Durch die Baumdarstellung sieht man sehr gut, welche Gruppe welche Segmente oder Untergruppen enthält. So eine Segmentgruppe kann, genau wie ein einzelnes Segment, unter Umständen mehrfach innerhalb einer Datei auftreten.
Bei Segmentgruppen ist das eigentlich immer so, sonst bräuchte es sie nämlich nicht.
Im Bild erkennt man an den gelben Ordner-Symbolen, welches Segment nur einmal auftreten und welches Segment oder welche Gruppe sich in den Daten wiederholen kann (blau). Was EDIFACT etwas kompliziert macht ist die Regel, nach der die einzelnen Segmente an bestimmten Positionen der Dateien auftreten können. Nehmen wir mal das RFF-Segment. Da stehen Referenzen drin, zum Beispiel auf andere Dokumente. So ein RFF kann im Prinzip direkt nach dem BGM kommen – das ist dann das, das in SG1 steht. Kommt danach ein NAD, ist klar, dass wir zur SG2 weitergegangen sind. Kommt nun noch einmal ein RFF, kann es unmöglich dasselbe in SG1 sein, sondern muss zwangsweise das in SG4 sein. Und das wiederum heißt, dass zwischen dem NAD und dem RFF zumindest noch ein ERC kommen muss, sonst ist die Datei kaputt. Kompliziert, oder? Also noch einmal im konkreten Beispiel, aber nur auf die Segmentkennungen verkürzt und um ein paar andere Segmente ergänzt:
| UNB | |
| UNH | |
| BGM | |
| DTM | Datums- und Zeitangaben (DTM = Date and Time) global zu dieser Nachricht |
| RFF | Das ist das RFF in SG1, Referenzen dieser Nachricht auf andere Dokumente (vielleicht eine Auftragsnummer) |
| DTM | Das DTM in SG1, zum Beispiel Zeitangaben aus dem referenzierten Dokument (Auftrag vom …) |
| RFF | Noch mal das RFF in SG1, also wird die SG1 wiederholt |
| DTM | Das DTM in der zweiten Belegung der SG1 |
| NAD | Damit haben wir SG2 erreicht, die Adressangaben und Kontaktinformationen |
| NAD | Und auch die wiederholt sich, wenn auch nur mit dem NAD-Segment alleine |
| ERC | Jetzt sind wir bei SG3 (Fehlerinformationen) |
| FTX | Freitext zur Fehlerinfo |
| RFF | Und dieses RFF ist jetzt das in der SG4 |
| FTX | Dieser Freitext gehört zur Referenz der SG4 |
| FTX | und der auch |
| UNT | |
| UNZ |
Würde das Segment ERC fehlen, dürfte auch keines der folgenden mehr auftauchen, erst wieder das UNT. Auch das sieht man im Bild: Die SG3 ist zwar optional (sie kann 0 bis
999 mal auftreten), aber wenn sie genutzt werden soll, dann muss das ERC-Segment vorkommen. Das ist eine allgemeine Regel: Das erste Segment jeder Segmentgruppe ist
bei Nutzung dieser Gruppe verpflichtend. Der Grund ist ganz einfach, dass man ohne ein ERC ja gar nicht wüsste, dass nun eben die SG3 kommt.
Weiterentwicklung
So kompliziert der Aufbau von EDIFACT-Dateien ist, es gibt auch ein paar gute Nachrichten: Die einzelnen Bestandteile, die Segmente und Composites, sind immer gleich aufgebaut. Egal, in welcher Art Nachricht also ein RFF-Segment vorkommt, es sieht immer gleich aus. Und sogar ein Feld mit einer bestimmten Nummer (wie 1153, Felder sind in EDIFACT nummeriert) hat immer denselben Typ, dieselbe maximale Länge und dieselbe Bedeutung. Der Aufbau von Segmenten und Composites wird natürlich über die Versionen hinweg erweitert, und ein Feld kann dabei z.B. auch mal länger werden, aber innerhalb einer Version sehen ein RFF oder NAD immer gleich aus. Auch eine C506, falls sie in mehreren Segmenten verwendet werden sollte, wird überall gleich aussehen.
Hier mal die direkte Gegenüberstellung der APERAK-Nachricht in Version D96A und D10B, jeweils mit dem Aufbau des ersten RFF-Segmentes:
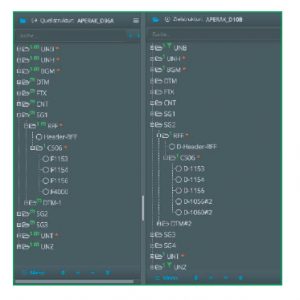
Sie sehen, man hat inzwischen eine andere Segmentgruppe vor die Referenzen geschoben, sodass RFF nun die SG2 einleitet. Außerdem hat man das Feld 4000 (Reference version number) durch die beiden Felder 1056 (Version identifier) und 1060 (Revision identifier) ersetzt. Diese kommen übrigens, mit derselben Bedeutung, aber in anderem Kontext, auch im Segment BGM und im neu hinzugekommenen Segment DOC der jetzigen SG1 vor.
Daher hier die zusätzliche Nummerierung mit #2, eine Eigenart dieses Konverters. Auch das „F“ bzw. „D-“ vor den eigentlichen Feldnamen hat mit dieser speziellen Software zu tun.
Allgemeine Steuersegmente
UNA: Vereinbarung der Sonderzeichen
In genau dieser Reihenfolge kommen:
- Trennzeichen zwischen Werten innerhalb einer „Composites“
- Trennzeichen zwischen eigenständigen Werten und ganzen Composites
- Dezimaltrenner
- Maskierungszeichen für Sonderzeichen, die selbst im Wert vorkommen
(Beispiel: „Firma Reibach + Söhne“, da muss ein ? vor das +, also Firma Reibach ?+ Söhne. Sonst würde das + als Trennzeichen interpretiert). - Das Leerzeichen war in EDIFACT-Syntax V3 noch reserviert, in EDIFACT-Syntax V4 kann dort ein „repetition character“ stehen für ein neues Feature, das zum Glück nicht genutzt wird
- Das Segment-Ende-Zeichen
Die Zeichen :+.? ‚ sind Standard; werden diese in einer Datei verwendet, kann das UNA-Segment entfallen.
UNB: Kopfdaten der Übertragung (Datei)
Die wichtigsten globalen Informationen über die ganze Datei wie Character Set (siehe unten), Absender, Empfänger, Datum und Nachrichtenreferenz. Im Beispiel sind alle Pflichtfelder belegt:
- UNB+UNOC:3+ILN Absender+ILN Empfänger+130230:1025+98765′
UNOC gibt das Character Set an, also die im Dokument verwendbaren Zeichen. - Die 3 bezeichnet die EDIFACT-Syntax Version 3, inzwischen gibt es schon Version 4 (aber darauf müssen wir hier nicht eingehen).
- Dann kommen Identifikationen für Absender und Empfänger, hier könnten auch einfach Firmennamen stehen.
- Nun Datum und Uhrzeit der Nachricht
- Am Ende steht eine Übertragungs-Referenznummer, die identisch auch im UNZ-Segment u finden ist. Dies identifiziert diese Datei eindeutig gegenüber den beteiligten Parteien, sollte also zwischen diesen beiden nur ein einziges Mal verwendet werden.
UNH: Kopfdaten der einzelnen Nachricht
Laufnummer und grundlegende Informationen über die einzelne Nachricht.
UNH+1+ORDERS:D:96A:UN‘
- Dies ist die erste Nachricht innerhalb der Datei bzw. Gruppe
(die 1 findet sich im zugehörigen UNT wieder) - Es handelt sich um einen Auftrag (ORDERS)
- Die Nachricht ist im Format der Version D96A verfasst und hält sich an den UNECE-Standard, also kein Subset wie EANCOM
UNT: Ende der einzelnen Nachricht
Anzahl aller Segmente in dieser Nachricht, einschließlich UNH und UNT, und die Laufnummer der Nachricht, die auch schon im zugehörigen UNH stand.
UNZ: Ende der gesamten Datei
Anzahl der Nachrichten in dieser Datei und Übertragungs-Referenznummer, die auch im UNB steht.
Die Zähler und Referenznummern in den Segmenten UNT und UNZ dienen Kontroll-Zwecken. So kann man schnell erkennen, ob einzelne Segmente oder ganze Nachrichten fehlen oder evtl. fälschlich mit reingerutscht sind.
BGM: Beginn einer Nachricht
Hier finden sich noch einmal Angaben über die Art der Nachricht (220 = Order = Auftrag) und ein paar Zusatzinfos (z.B., ob der Auftrag zurückgezogen werden soll o.ä.).
Charset SET
EDIFACT-Dateien können in verschiedenen Character Sets auftauchen. Das Character Set gibt die Zeichen vor, die innerhalb der Datei genutzt werden können, und steht im UNB-Segment.
Die wichtigsten sind:
- UNOA: Nur Großbuchstaben, Ziffern, Leerzeichen und einige wenige Sonderzeichen wie das =
- UNOB: Zusätzlich zu UNOA sind auch Kleinbuchstaben und ein paar mehr Sonderzeichen erlaubt
- UNOC: Im Prinzip alles, was im Encoding Latin1 alias ISO-8859-1 vorkommen darf
- UNOY: Der Zeichensatz, der mit Unicode abgebildet werden kann, also eigentlich alles.
Dazwischen werden noch diverse Latin-x-Zeichensätze sowie Arabisch und Hebräisch abgebildet durch UNOD bis UNOK.
So weit, so klar. Aber jetzt kommt das Fiese:
Da ein System, das eine EDIFACT-Datei verarbeitet, nicht unbedingt wissen kann, welches Character Set denn zu erwarten ist, muss es das aus dem UNB-Segment herauslesen. Spätestens, wenn man UNOY nutzt und die Datei in UTF16, also 2-Byte-codiert daherkommt, macht das nicht wirklich Spaß. Daher wurde folgendes festgelegt:
Das UNA-Segment (falls vorhanden) und das UNB-Segment müssen immer ASCII-kodiert sein, auch, wenn es ab dem BGM kyrillisch oder in UTF16 weitergeht. So ist das mit der Globalisierung: Viel Geschäft, aber auch jede Menge Stolpersteine …
Freiheitsgrade
Zum Abschluss noch ein wichtiger Punkt:
EDIFACT bietet unglaublich viele Freiheitsgrade. Angefangen bei den Qualifiern bis hin zu der Frage, in welches Segment wo in der Nachrichtenstruktur man welche Informationen verpackt.
Ein Beispiel für die vielen, möglichen Qualifier ist das NAD-Segment. Man kann für den Käufer den Qualifier BY verwenden. Genau so gut könnte man aber auch BS (Bill and ship to) nehmen oder CN (Consignee = Adressat) oder wahrscheinlich noch ein paar andere.
Beim Lieferanten sieht es kaum besser aus. Und wie auch im Artikel zu Inhouse-EDI-Systemen angemerkt, kann man auch die gesamten Adressinformationen an verschiedenen Stellen derselben Nachricht anbringen. Das NAD-Segment existiert in einer einzigen Nachrichtenart an mehreren Stellen, die meist mehrere Ebenen darstellen (Dokument, Position, Detail, …), und es gibt entsprechend viele Ansichten darüber, wo welche Adressen angegeben werden sollen oder müssen. Das hängt oft davon ab, welche Fähigkeiten die Systeme haben, aus denen die Daten stammen. Kennt ein System nur Adressangaben auf Lieferabruf-Ebene, kann man auch nur die Adressen auf oberster Ebene sinnvoll angeben.
Bietet es dagegen die Möglichkeit, zu jeder Position eigene Adressen anzugeben, wird diese Möglichkeit vermutlich auch genutzt und in einem ausgegebenen DELFOR abgebildet.
Es ist daher zwingend nötig, dass beide an einem EDI-Prozess beteiligten Seiten sich darüber verständigen, wie genau das jeweilige Nachrichtenformat genutzt werden soll. Das Allermindeste sind exakte Informationen, wie die Daten bereitgestellt bzw. erwartet werden, andernfalls ist keine saubere Umsetzung des Prozesses möglich. In der Praxis allerdings ist man immer wieder auf ein paar Beispieldaten und das try-and-error-Verfahren angewiesen, was zwar enorm Zeit (und Nerven) kostet, aber meist irgendwie auch funktioniert. Gerade in einem solchen Fall ist es wichtig mit einer Software zu arbeiten, die den Nutzer bei der Erstellung einer Anbindung durch einfache Bedienung und umfassende Testmöglichkeiten unterstützt.