
Was ist das?
Mit Fix Record oder Feste Länge ist der Aufbau diverser Datenformate auf unterster Ebene gemeint. Während bei CSV die einzelnen Werte durch Trennzeichen voneinander abgegrenzt werden, sind hier die Längen der Werte entscheidend. Und, wie auch bei CSV, die Reihenfolge. Aus diesen beiden Voraussetzungen folgt, dass jeder Wert im Datensatz eine genau festgelegte Start- und Endposition hat.
Ein einfaches Beispiel?
AK 4711 K0815 20130530 POS0001S123 0005000009990 POS0002H456 0003000017950
Das ist ein extrem simples Beispiel, aber für die Grundlagen reicht’s.
Dröseln wir die Zeilen auf.
AK 4711 K0815 20130530
- AK soll hier für den Auftragskopf stehen. Dies ist die Satzartkennung, an der eine Software (oder auch der Mensch) erkennt, was für ein Datensatz kommt. Sie ist drei Stellen lang, hier aufgefüllt mit einem Leerzeichen.
- 4711 ist die Auftragsnummer, 8 Stellen lang, mit Leerzeichen aufgefüllt.
- K0815 ist die Kundennummer, ebenso lang und aufgefüllt.
- 20130530 schließlich ist das Auftragsdatum, Format yyyymmdd, also 8-stellig.
- Dahinter steht noch ein Leerzeichen, das sehen Sie nur jetzt nicht (aber später).
POS0001S123 0005000009990
- POS ist die Kennung für die Position. Da sie bereits dreistellig ist, muss kein Leerzeichen mehr angefügt werden.
- 0001 ist die Positionsnummer. Sie wird auf eine Länge von 4 Zeichen mit führenden Nullen aufgefüllt.
- S123 ist die Artikelnummer, mit folgenden Leerzeichen auf 8 Zeichen gefüllt.
- 0005 wurde mit Nullen auf Länge 4 aufgefüllt, das ist die Menge.
- 000009990 schließlich soll 9.99 darstellen, vorne mit Nullen aufgefüllt, und statt eines Dezimaltrenners wurde einfach definiert, dass eben immer die letzten drei Ziffern die Nachkommastellen darstellen. Gesamtlänge 9.
Rechnen Sie die Längen dieser Felder mal zusammen! Was kommt raus? Beide Male 28. Um das zu erreichen, wird die Kopf-Zeile noch mit einem Leerzeichen am Ende aufgefüllt. Gäbe es mehr als diese beiden Satzarten, wären alle so lang, dass die längste Platz hat. Oder man wählt gleich eine übliche „Computer-Zahl“ wie 64, 128 oder 256. Das ist bei solchen Datenformaten ziemlich üblich, aber nicht wirklich zwingend. Im Prinzip kann jede Satzart eine eigene Länge haben, doch die muss dann genau festgelegt sein. Durch diese Regel, dass jede Satzart ihre Länge einzuhalten hat, kann man auf Zeilentrenner verzichten (viele Systeme mögen so was auch gar nicht) und kann alles hintereinander schreiben:
AK 4711 K0815 20130530 POS0001S123 0005000009990POS0002H456 0003000017950
Jetzt sehen Sie auch das Leerzeichen am Ende des Kopfsatzes.
Satzarterkennungen
Satzartkennungen
Eine Nachricht besteht üblicherweise aus verschiedenen Teilen, zum Beispiel einem Kopf wie oben, oft auch einem Nachsatz am Ende, dann Informationen zu einzelnen Sendungen oder Abrufen oder was auch immer, Details zu Positionen und so weiter. In vielen Formaten steht die Satzart gleich ganz vorne. Das ist ungemein praktisch, denn dann kann man nach einer einfachen Regel vorgehen:
Man sehe sich die ersten Zeichen der Datei an. Da steht, welche Satzart kommt. Anhand der Format-Definition weiß man nun, wie lang diese Satzart ist und welche Werte wo stehen. Und danach muss man sich einfach nur die nächsten Zeichen anschauen, dann weiß man, was als nächstes kommt.
Regeln für die Praxis
Regeln für die Praxis
Das mit der exakten Länge jeder Satzart ist schöne Theorie, in der Praxis gibt es da ein paar Varianten. Wenn man ganz puristisch sein will, hat tatsächlich jede Satzart exakt ihre Länge einzuhalten und dazu notfalls mit Leerzeichen aufgebläht zu werden. Außerdem gibt es keine Zeilentrennung, alles steht direkt hintereinander. Ist wunderbar maschinenlesbar, für einen Menschen allerdings nicht wirklich schön (siehe oben). Daher kommt es häufig vor, dass die einzelnen Satzarten doch durch Zeilenumbrüche voneinander getrennt sind. Das wiederum ist für den Computer nicht ganz so schön, weil er die Zeilenumbrüche als überflüssige Zeichen erkennen und bei der Längenberechnung berücksichtigen muss.
Eine Satzart mit 128 Zeichen hat so eigentlich 129 oder 130 (LF oder CRLF).
Wenn man grad dabei ist und die Satzarten durch Zeilenumbrüche trennt, kann man auch gleich die Füllzeichen am Ende weglassen. Damit wäre der Kopfsatz oben plötzlich nur noch 27 Zeichen lang, statt der eigentlich vorgegebenen 28. Nicht gerade das, was man sich ursprünglich bei diesem Format gedacht hat, aber in der freien Wildbahn trifft man diese Variationen immer wieder an.
Es gibt ein paar weitere Regeln, die nicht unbedingt zwingend, aber in bekannten Fix-Record-Datenformaten umgesetzt sind:
- Zahlenwerte werden meist mit führenden Nullen auf ihre definierte Länge aufgefüllt.
- Nicht-Zahlenwerte dagegen werden mit Leerzeichen, und zwar rechts vom eigentlichen Wert, aufgefüllt.
- Fließkommazahlen werden meist nicht mit Dezimaltrenner dargestellt, sondern mit einer festen Anzahl impliziter Nachkommastellen. Aus 3.05 wird dann z.B. (mit Auffüllung vorweg): 00003050. Hier sind also die letzten drei Stellen implizite Nachkommastellen. Wie viele es jeweils sind, wird normalerweise für jeden Wert einzeln vorgegeben.
- Auch ein Datum oder eine Zeitangabe kommt normalerweise ohne Trennzeichen aus, statt dessen sind die Formate yymmdd bzw. yyyymmdd und hhmm bzw. hhmmss sehr verbreitet.
- Die Satzartkennungen stehen meist am Anfang, es gibt aber auch (üblicherweise nur in der jeweiligen Firma genutzte) Formate, die die Kennungen erst irgendwo mitten in den Daten ansiedeln.
- Gibt es nur eine einzige Art von Datensätzen, kann man natürlich ohne Kennung auskommen.
Datenformate, die auf Fix Record aufbauen
Die zwei bekanntesten Vertreter sind Fortras und VDA (hier die älteren Formate). Beide wurden von Konsortien entwickelt und verabschiedet und haben ihre eigenen Artikel hier. Dazu kommt noch das ältere IDOC-Format von SAP, dem ebenfalls ein eigener Artikel gewidmet ist. Darüber hinaus werden aber oft z.B. Exporte aus Datenbanken so aufgebaut, vor allem, wenn die Daten aus einer AS400 alias IBM iSeries kommen. Da hat jede Spalte der Tabelle ihre definierte Länge, und oft genug steht alles gleich in einem immer gleich langen String in einer einzigen Spalte. Auch einige andere Programme nutzen für Ex- oder Importe Dateien im Fix-Record-Format, da diese sehr einfach zu lesen sind. Man setzt den Dateizeiger einfach immer z.B. 128 Zeichen weiter und hat automatisch den nächsten Datensatz, und auch innerhalb des Datensatzes springt man nur an die von Anfang an bekannten Positionen, um an die gewünschten Werte zu kommen. Als die meisten Programme ihre Daten noch in eigenen Strukturen auf Platte (oder gar Diskette) hielten, anstatt allgemein verfügbare Datenbanken zu nutzen (die es damals nicht so leicht verfügbar gab), war das die praktikabelste Lösung, wenn nicht alles in den Speicher passte.
Was ist VDA?
Das Kürzel VDA steht eigentlich nicht für ein Datenformat, sondern für den Verband der deutschen Automobilindustrie. Dieser wiederum hat für seine Mitglieder sogenannte Empfehlungen herausgegeben, wie sie im EDI-Umfeld ihre Daten untereinander austauschen sollen. Diese Empfehlungen haben Nummern, die letztlich für verschiedene Nachrichtentypen stehen.
Die früheren Empfehlungen beinhalten noch eigene Formate, die wiederum strukturell Fix-Record-Formate sind. Um die wird es in diesem Kapitel gehen. Inzwischen schwenkt der VDA auf die Benutzung von EDIFACT um (ein Beispiel ist die VDA-Empfehlung 4938), wodurch sich langsam ein eigenes Subset (siehe EDIFACT-Kapitel) bildet.
Nachrichtentypen
Nachrichtentypen
Sehr gebräuchlich sind die Typen (alias Empfehlungen) 4905 (Lieferabrufe), 4906 (Rechnungen), 4913 (Lieferscheine) und 4920 (Speditionsaufträge), aber es gibt noch viele mehr.
Warum die alle mit 49 anfangen? Fragen Sie was Leichteres … Eine lange Liste der verfügbaren Empfehlungen finden Sie im Wikipedia-Artikel zum VDA.
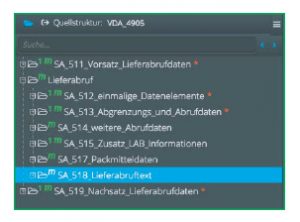 |
| Aufbau des VDA 4905 Lieferabrufes, dargestellt in Lobster_data |
Und so sieht das Format für Lieferscheine (4913) aus:
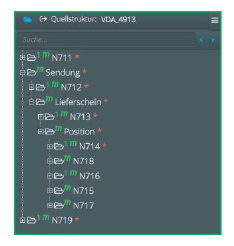 |
| Aufbau des VDA 4913 Lieferscheines, dargestellt in Lobster_data |
Wundern Sie sich nicht über die unterschiedliche Benennung der Satzarten, die ist in dieser Software frei wählbar und ein Stück weit Geschmackssache. Dem einen reicht ein „N[ode] 711“, der andere bevorzugt das ausführliche „S[atz]A[rt]_511_Vorsatz_Lieferabrufdaten“.
Aufbau der Satzarten
Aufbau der Satzarten
51101KdNr LiefNr 0045600457130209 |ENDE
Das (alles vor dem „|ENDE“) ist der Vorsatz (quasi der Datei-Kopf) zu einem VDA 4905 Lieferabruf. Die Werte sind im Einzelnen:
511: Kennung des Vorsatzes, immer 3 Zeichen
01: Versionsnummer, immer 2 Zeichen, vorn mit 0 aufgefüllt
KdNr: Kundennummer, immer 9 Zeichen, aufgefüllt mit folgenden Leerzeichen
LiefNr: Lieferantennummer, auch immer mit folgenden Leerzeichen auf 9 aufgefüllt
00456: Laufnummer der vorangegangenen Übertragung, immer 5 Zeichen, mit führenden Nullen aufgefüllt
00457: Laufnummer dieser Übertragung, ebenso lang und aufgefüllt
130209: Datum der Übertragung im Format yymmdd, also hier der 09. Februar 2013
Danach könnte noch mal ein Datum (das der Nullstellung) kommen, das hier aber fehlt, und dann noch 83 Leerzeichen. Warum, wird gleich erklärt.
Der Aufbau dieses Datensatzes, etwas tabellarischer dargestellt:
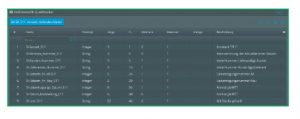 |
| Aufbau der VDA-Satzart 511, dargestellt in Lobster_data |
Rechnen Sie die Längen dieser Felder mal zusammen! Was kommt raus? 128. Und auch jede andere Satzart in so einem VDA 4905 Lieferabruf ist exakt 128 Zeichen lang. Um das zu erreichen, wird eben jede Zeile noch mit einer gewissen Anzahl Leerzeichen am Ende aufgefüllt.
Grundregeln VDA
Grundregeln VDA
Jede VDA-Nachricht beginnt mit einem Vorsatz, in dem die beteiligten Parteien, die Nummern der vorigen und jetzigen Übertragung und das Übertragungsdatum enthalten sind. Darüber hinaus gibt es meist noch ein paar weitere Angaben, die aber von Typ zu Typ variieren.
Ebenso endet jede Nachricht mit einem Nachsatz, in dem die Anzahl der einzelnen Satzarten innerhalb der Nachricht aufgeführt ist. Beispielhaft hier für den Lieferschein, VDA 4913:
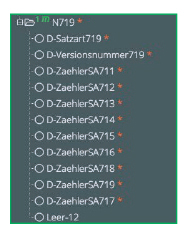 |
| Der Nachsatz des VDA 4913 Lieferscheines, dargestellt in Lobster_data |
SieSieht ganz so aus, als sei die Satzart 717 erst später dazugekommen, weshalb ihr Zähler hinter dem für den Nachsatz 719 liegt.
Jede Satzart beginnt übrigens immer mit ihrer Kennung (drei Zeichen) und einer Versionsnummer (zwei Zeichen, aufgefüllt mit führender Null). Diese Versionsnummer bezieht sich tatsächlich auf die einzelne Satzart. Es kann also vorkommen, dass innerhalb einer Nachricht munter Satzarten verschiedener Versionen gemischt werden. Zahlenwerte werden grundsätzlich mit führenden Nullen auf die nötige Länge aufgefüllt, alle anderen Werte mit folgenden Leerzeichen.
Was ist FORTRAS?
Fortras steht heute für einen Nachrichtenstandard, der für den Datenaustausch zwischen bzw. mit Speditionen genutzt wird. Hier geht es zum Glück recht übersichtlich zu. Es gibt drei gebräuchliche Nachrichtentypen, das sind Verladeinformationen alias Borderos, Statusberichte und Entladeberichte. Diese wiederum gibt es in mehreren Versionen, genannt „Release“. Release 2 bis 5 (die 1 wurde wohl gleich übersprungen) enthält alle drei Nachrichtentypen, in Release 6 gab es nur kleine Änderungen an den Borderos, und für Release 100 wurden dann alle drei noch mal ordentlich überarbeitet.
Da ein augenfälliger Unterschied zwischen diesen Versionen die Länge der einzelnen Satzarten ist (128 Zeichen bei Release 2–6, 512 Zeichen bei Release 100), kann man die ganze Vielfalt der üblichen Fortras-Nachrichten in folgender, kurzer Liste zusammenfassen:
- Release 2-6 mit 128 Zeichen Satzlänge:
- BORD128: Bordero (Verladeinfos)
- STAT128: Statusdaten
- ENTL128: Entladebericht
- Release 100 mit 512 Zeichen Satzlänge:
- BORD512: Bordero (Verladeinfos)
- STAT512: Statusdaten
- ENTL512: Entladebericht
Beispiel: BORD512
Hier mal die Satz-Struktur eines Borderos im Release 100:
 |
| Struktur eines BORD512, dargestellt in Lobster_data |
Und passend dazu das Beispiel einer solchen Datei, auf die Satzartkennungen und ein paar wesentliche Werte reduziert:
@@PHBORD512 1234 56 7 8 SENDER EMPFAENG A00STDSendungs-Kopfdaten B00001SHPVersenderangaben Sendung 1 B10001TELTelephonnummer B00001CONEmpfaengerangaben B10001TELTelephonnummer D00001001Packstücke, Positionsangaben, Gewichte usw. F00001001Barcode1 F00001001Barcode2 G00001Sendungssummen H00001Text1 H10001Text2 H10001Text3 B00002SHPVersenderangaben Sendung 2 ... die zweite Sendung ... J00Summen zu allen Sendungen Z00Kontrollsatz @@PT
In der Baumdarstellung oben mag es etwas seltsam wirken, dass die Satzarten B00 und B10 zwei mal auftauchen, einmal mit dem Zusatz „-SHP“, einmal als „Adresse_Rest“. Den Grund dafür kann man an den Daten erkennen: Jede Sendung innerhalb der Datei beginnt mit den Adressangaben zum Versender (Shipper = SHP). Danach können aber verschiedene weitere Adressangaben auftauchen, wie eben die zum Empfänger (Consignee = CON). Und zu jeder Adresse gibt es noch Kontaktinformationen wie die Telefonnummer
im B10-Satz. Diese Logik, dass die SHP-Adresse eine Sendung einleitet, wird in dieser Baumdarstellung eben auf diese spezielle Weise abgebildet.
Wie schon gesagt, jede Satzart in Fortras Release 100 ist 512 Zeichen lang. Also ist in einer realen Datei auch normalerweise jede Zeile mit Leerzeichen auf die entsprechende Länge aufgefüllt, falls die enthaltenen Daten nicht genug Zeichen hergeben. Und wie im allgemeinen Teil zu Fix Record schon gesagt, wird das nur gemacht, wenn man sich strikt an die Regel der festen Satzlänge hält. Nutzt man stattdessen Zeilenumbrüche, werden auch gerne mal die Füllzeichen hinten raus weggelassen.
Zwei Zeilen verdienen noch besondere Aufmerksamkeit: die mit @@ vorne dran.
@@PHBORD512 1234 56 7 8 SENDER EMPFAENG
Alle Fortras-Formate beginnen mit solch einer Zeile. Immer steht @@PH am Anfang, danach kommt das Formatkürzel, wie es auch schon oben in der Liste steht (also alles von BORD128 bis ENTL512), und danach Angaben zu Sender und Empfänger der Daten und ein paar Kleinigkeiten.
@@PT
Zeigt das Ende der Datei an.
Wie bei VDA werden Zahlen links mit Nullen, andere Werte rechts mit Leerzeichen aufgefüllt. Auch Fortras verwendet implizite Nachkommastellen, so wird aus einer 3.05 z.B. eine 00003050.